Flask with Amazon S3 Part VI
Using Sessions to Change Buckets
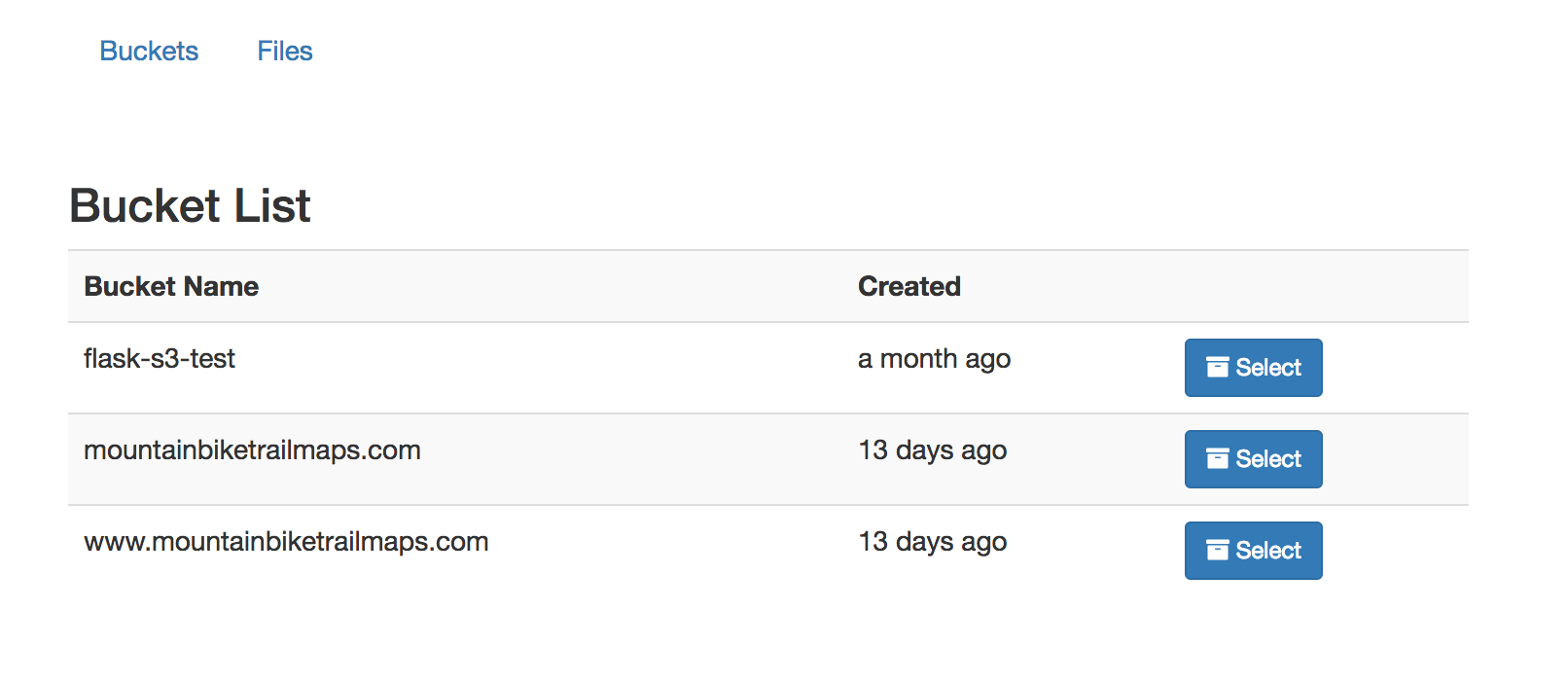
Currently, we are able to list our buckets on our home page. However, we can only list the files for the bucket that was configured using our environment variables. Since we’ve gone though the trouble of listing our buckets, it would be nice if we could select one from the home page and view its contents.
We’ll begin by added a “select” button to each row in our buckets list. This will be placed inside a form so we can use a hidden input tag so we can post the bucket name. We will use our index route to handle the post request.
templates/index.html
<table class="table table-striped">
<tr>
<th>Bucket Name</th>
<th>Created</th>
<th></th>
</tr>
{% for bucket in buckets %}
<tr>
<td>{{ bucket['Name'] }}</td>
<td>{{ bucket['CreationDate'] | datetimeformat }}</td>
<td>
<form class="select-bucket" action="{{ url_for('index') }}" method="post">
<input type="hidden" name="bucket" value="{{ bucket['Name'] }}">
<button type="submit" class="btn btn-primary btn-sm">
<i class="fa fa-archive"></i>
Select
</button>
</form>
</td>
</tr>
{% endfor %}
</table>
Although our form is ready, our route will not be able to handle a post request. By default, any route we setup will only be able to handle get requests. So, we need to pass a list of accepted request methods into our route.
app.py
...
@app.route('/', methods=['GET', 'POST'])
...
Once we have this setup, we can check to see which request method we received. This will let us know whether a form was submitted or whether to load the index page. If the form was submitted, we will use a Flask session to store the bucket name.
app.py
from flask import Flask, render_template, request, redirect, url_for, flash, \
Response, session
...
@app.route("/", methods=['GET', 'POST'])
def index():
if request.method == 'POST':
bucket = request.form['bucket']
session['bucket'] = bucket
return redirect(url_for('files'))
else:
buckets = get_buckets_list()
return render_template("index.html", buckets=buckets)
Above: we also imported session from Flask so we can set a new session variable. If the request method is post, we will set the bucket name in a session variable, then redirect the user to the files page. Right now, this won’t work because the user will still be shown the files from the bucket that was configured using the environment variables. We will need to modify our resources.py file to fix this.
In resources.py, we need to import session as well. Then, in our get_bucket() function, we will check to see if a bucket is set in the session. If so, we will return the bucket object for that bucket. If not, we will return the bucket that was set in the configuration.
resources.py
...
from flask import session
...
def get_bucket():
s3_resource = _get_s3_resource()
if 'bucket' in session:
bucket = session['bucket']
else:
bucket = S3_BUCKET
return s3_resource.Bucket(bucket)
We need to check if the bucket key is set in the session. Otherwise, we would get an error from not defining it.
One final thing to note before we try to run this: I found that I had made an error the file type filter. In the try-except block, I had put in a pair of parentheses in the except KeyError statement. If we run into any mimetypes that don’t match, it will result in an error, causing our page to crash. Here is the simple fix:
filters.py
def file_type(key):
file_info = os.path.splitext(key)
file_extension = file_info[1]
try:
return mimetypes.types_map[file_extension]
except KeyError:
return 'Unknown'
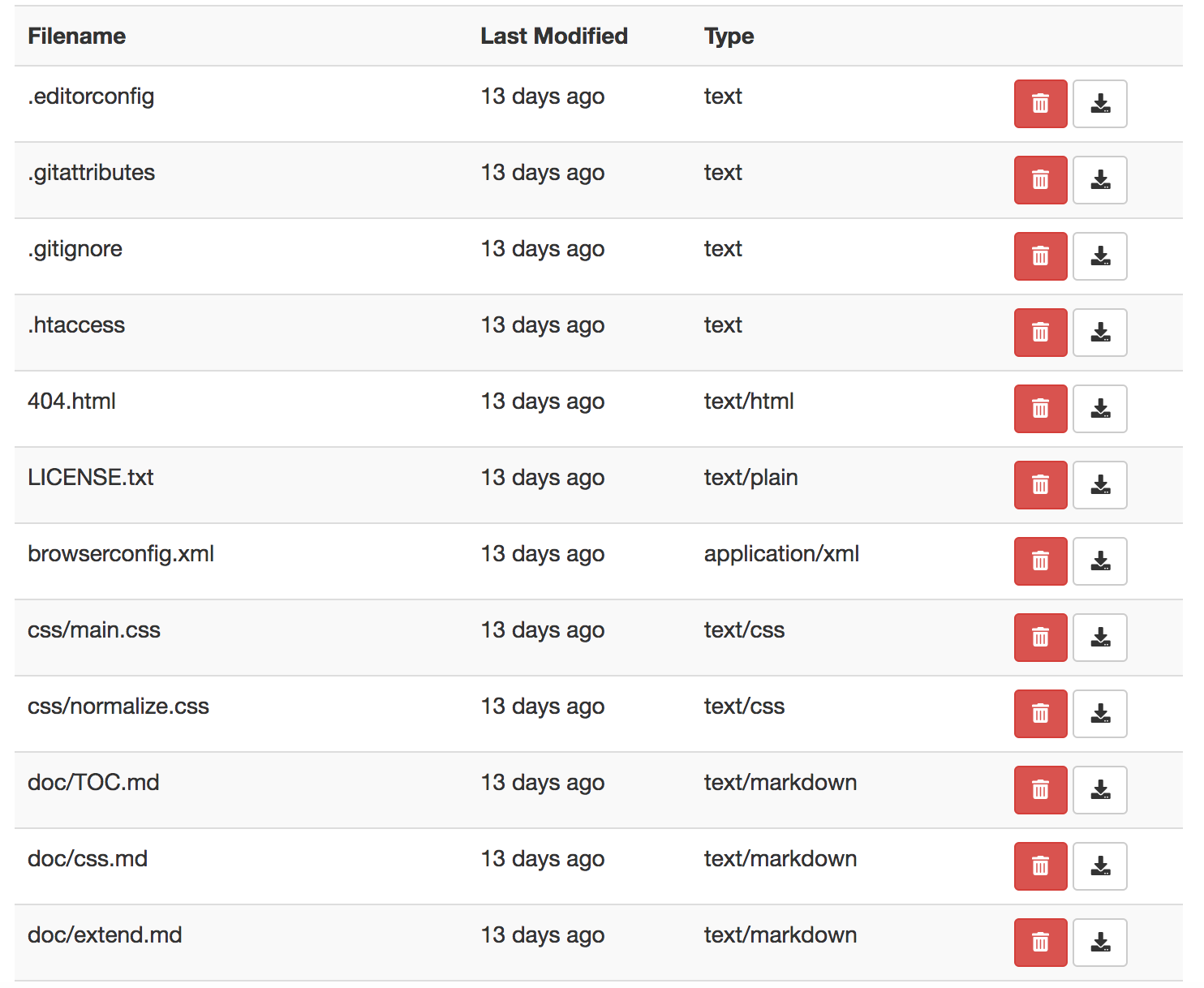
In my test data for this post, I had created a new bucket called “www.mountainbiketrailmaps.com”. This was from another post I created which entailed setting up a static website using Amazon S3. It was based on files from HTML5 Boilerplate. When viewing the files, the filetypes were missing for some. These included dotfiles (mainly configuration files that start with a dot “.”, i.e. .gitignore) and Markdown files. We can improve our filter to accommodate these.
First, let’s check to see if the file is a “dotfile”. If so, we’ll just return “text”. We can check to see if the file starts with a “.”. Based on our current use case, we do not expect there to be a file extension since the the only dot should be the very first character. As a result, we will expect an empty string for the file extension.
filters.py
...
def file_type(key):
file_info = os.path.splitext(key)
file_extension = file_info[1]
try:
return mimetypes.types_map[file_extension]
except KeyError:
filetype = 'Unknown'
if file_info[0].startswith('.') and file_extension == '':
filetype = 'text'
return filetype
We put this logic in the KeyError block because there’s no need to check it if there is a mapping within the mimetypes.
This should satisfy our use case when it comes to dotfiles. However, our Markdown files with a “.md” extension are still showing up as “Unknown”. To fix this, we will start a whitelist of file types we want to check should we run into the KeyError exception (and the file is not a dotfile). By starting a whitelist, more filetypes can easily be added later.
Near the top of the filters.py, we can setup a new dictionary for any additional filetype we choose to configure.
filters.py
import os
import mimetypes
import arrow
additional_file_types = {
'.md': 'text/markdown'
}
...
Next, in our file_type filter, we can check the dictionary lookup in the KeyError block.
filters.py
def file_type(key):
file_info = os.path.splitext(key)
file_extension = file_info[1]
try:
return mimetypes.types_map[file_extension]
except KeyError:
filetype = 'Unknown'
if file_info[0].startswith('.') and file_extension == '':
filetype = 'text'
if file_extension in additional_file_types.keys():
filetype = additional_file_types[file_extension]
return filetype
With this change, we should have resolved all the unknowns: